Clusters & sync premium
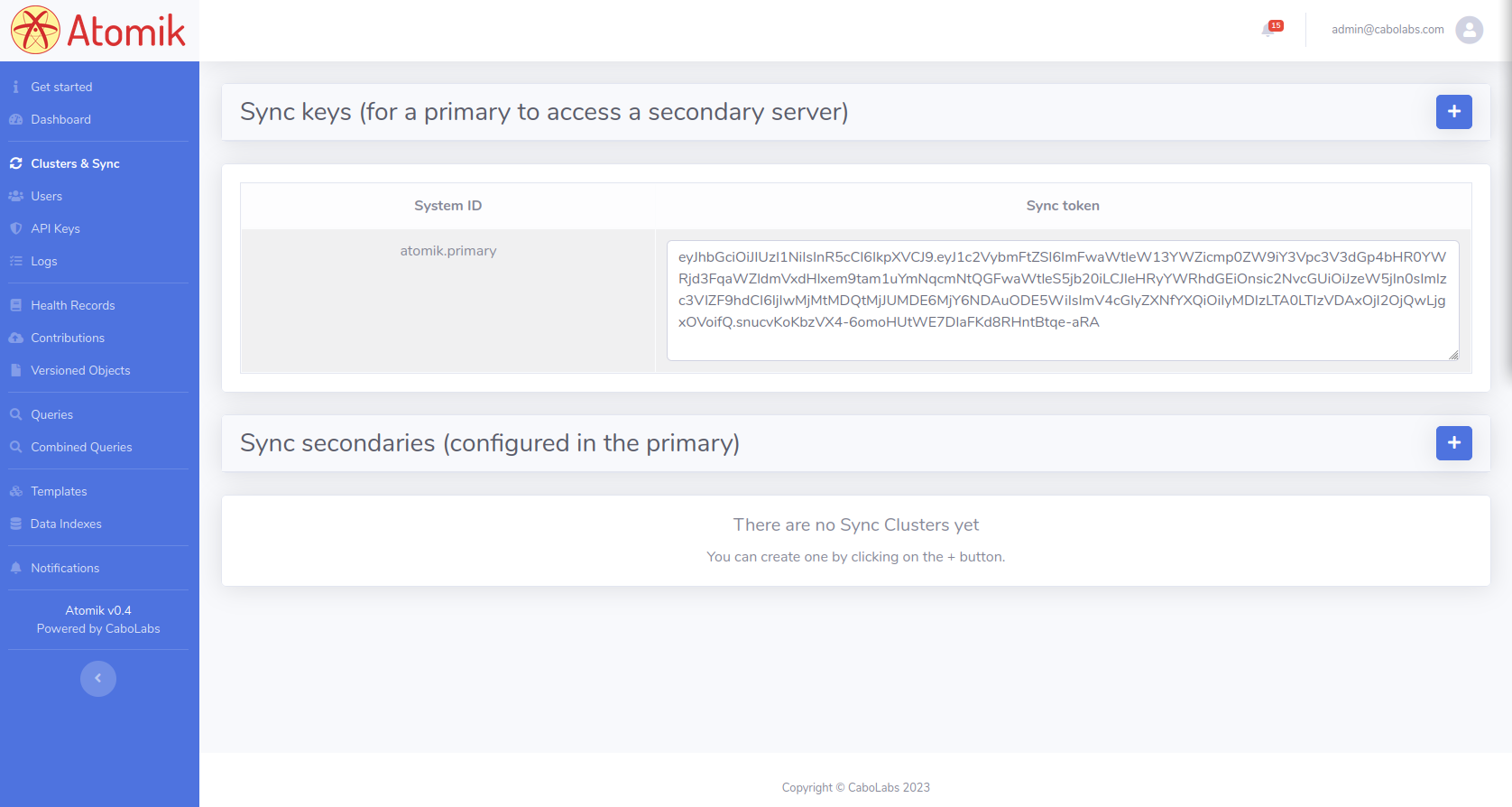
This section allows to configure the current server to be a primary or secondary in an Atomik Cluster. The primary is an Atomik instance that receives commits and queries from clients, and synchronizes the data committed to the secondary instances. The secondaries (one or many) receive data only from the primary and can be queried by clients.
Primary and Secondary servers
So Atomik clustering follows a "write to one, read from many" approach, where the read could be load balanced. THough new topologies could be explored, for instance clusters many primaries and secondaries, or even symmetric clusters (all can receive writes, queries and can sync with the rest).
To define an Atomik instance as a secondary, you only need to generate the Sync API Key that will be configured in the primary to grant access to the Sync API of that secondary. The Sync API Key is actually an API Access Token.
To define an Atomik instance as the primary, you need to create the configurations for all the secondaries the primary will sync data to. That configuration includes setting mainly the IP address, port number and Sync API Key of each secondary.