Storing data
Atomik supports storing data from the REST API, so it's only external systems that will create data in Atomik.
Data could be created, modified, amended and even deleted following the openEHR specifications. More about this in the Data versioning section.
Types of data supported
Atomik supports storing data for these openEHR classes:
- EHR and EHR_STATUS
- FOLDER
- COMPOSITION
- ACTOR and ROLE
- PARTY_RELATIONSHIP
EHR and EHR_STATUS
Atomik implements the openEHR REST API endpoint POST /ehr to create an EHR. When an EHR is created, it's EHR_STATUS is also created. A client system could pass an EHR_STATUS or just send an empty request to that endpoint, and Atomik will create the EHR with the given EHR_STATUS or with a default one if no EHR_STATUS is provided.
FOLDER
In openEHR, an EHR can have one root directory and any amount of FOLDERs and sub FOLDERs inside that root directory. The openEHR REST API provides the POST /directory endpoint for creating and storing a new directory inside an EHR. Then you will use the PUT /directory to modify it's structure of subfolders and items like references to COMPOSITIONs.
When a create or update happens on an EHR directory, if FOLDERs contain references to items, Atomik will check if those items exist in the repository and will retrieve an error if any items don't exist, guaranteeing the data completeness and consistency of the repository.
COMPOSITION
For creating COMPOSITIONs Atomik supports the POST /composition endpoint.
ACTOR and ROLE
Atomik implemented a demographic REST API that is not part of the current openEHR REST API specification, because openEHR doesn't support the demographic model at the API level. The demographic API proposed by Atomik takes the same principles the current openEHR API has for other objects, like COMPOSITION, and applies them to the demographic classes (PERSON, ORGANISATION, AGENT, GROUP, ROLE and PARTY_RELATIONSHIP).
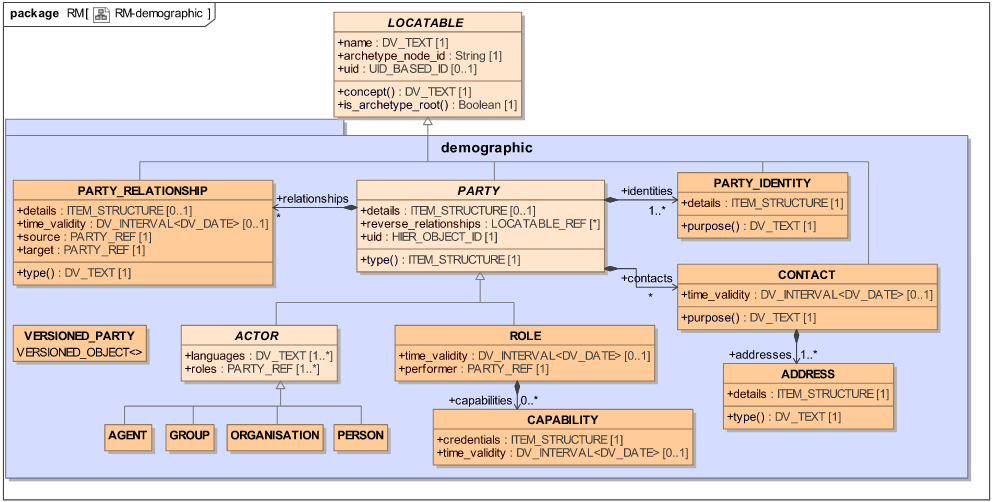
To create a new ACTOR (PERSON, ORGANISATION, AGENT or GROUP), Atomik provides a POST /actor endpoint in the REST API. If you want to assign a ROLE to any of those objects, you need to add the ROLE information inside the ACTOR object and it will be stored alongside the ACTOR. There is no endpoint to create a ROLE on it's own, it should be inside an ACTOR.
Note that an ACTOR can contain many ROLEs.
PARTY_RELATIONSHIP
Since PARTY_RELATIONSHIP is also a class from the demographic model, openEHR doesn't provide API endpoints to work with relationships. Atomik provides a POST /relationship endpoint that allows a client to create relationships between two existing ACTOR objects.
Note the POST /relationship endpoint will verify if the source and target of the relationship exist in the repository, to guarantee data completeness and consistency. If any of those references don't exist, the endpoint will return an meaningful error to the client of the API.
Data validation
Atomik's REST API does a two level data validation for all the types mentioned above. When new data is received by a POST /xxx endpoint, the first validation is syntactical, verifying the provided payload complies with the openEHR JSON or XML schemas. Once the payload is validated, it can be parsed into the corresponding object (COMPOSITION, FOLDER, PERSON, EHR_STATUS, etc). Once parsed, the object is validated against the Operational Template (OPT) that defines that specific object (the object has a reference to the template in the template_id field). This second level is a semantic validation. If an object passes both levels of validation, then it's stored. If there is an error on any level, a developer friendly error message is retrieved, so the client knows where is the problem and can fix it on their side.
Note those two validation levels are executed for all types and for both creation and modification operations.